 Here is a delightfully easy way to get an Excel spreadsheet from a search for Github users.
Here is a delightfully easy way to get an Excel spreadsheet from a search for Github users.
(See an exclusive offer for Brainfood subscribers below).
- Install Chome Extension AutoPagerize. It will allow appending the 2nd, 3rd, etc. search results pages to the bottom of the current page, creating one long page that contains all the results (or as many as you wish). It works in Google search results as well as in Github search results.
- Search for the languages and locations on Github – for example, language:java location:amsterdam:

- Scroll down, letting AutoPagerize create a long page containing as many results as you wish.
- Install and run Chome Extension Instant Data Scraper from webrobots.io.
Voila – you can now export scraped, parsed results into Excel:
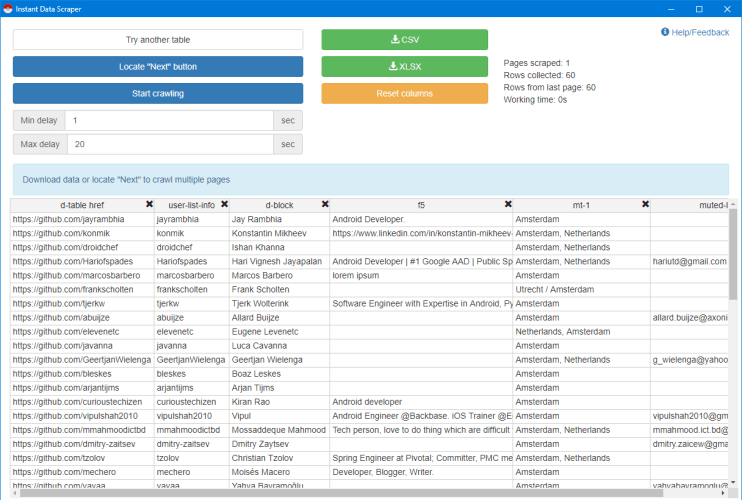
(Note that in this case there’s no need to locate the “Next” button since all the results are within the page.)
Enjoy!
Did you miss our webinar “Web Scraping For Recruiters”? This week’s presentation was sold out, and we are repeating it on Tuesday, August 6th, followed by an optional hands-on Workshop on August 7th. We will cover scraping tool selection and multiple tools such as Data Miner, Phantombuster, ZapInfo, Outwith Hub, and more. Seating is limited.