 Here is a delightfully easy way to get an Excel spreadsheet from a search for Github users.
Here is a delightfully easy way to get an Excel spreadsheet from a search for Github users.
(See an exclusive offer for Brainfood subscribers below).
- Install Chome Extension AutoPagerize. It will allow appending the 2nd, 3rd, etc. search results pages to the bottom of the current page, creating one long page that contains all the results (or as many as you wish). It works in Google search results as well as in Github search results.
- Search for the languages and locations on Github – for example, language:java location:amsterdam:

- Scroll down, letting AutoPagerize create a long page containing as many results as you wish.
- Install and run Chome Extension Instant Data Scraper from webrobots.io.
Voila – you can now export scraped, parsed results into Excel:
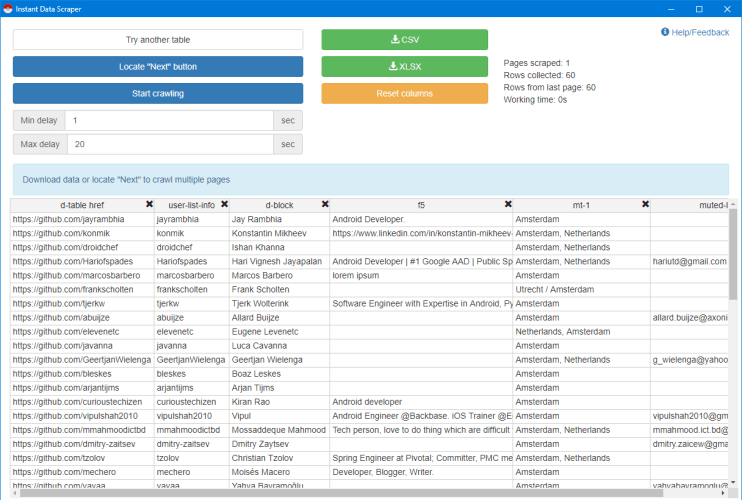
(Note that in this case there’s no need to locate the “Next” button since all the results are within the page.)
Enjoy!
Did you miss our webinar “Web Scraping For Recruiters”? This week’s presentation was sold out, and we are repeating it on Tuesday, August 6th, followed by an optional hands-on Workshop on August 7th. We will cover scraping tool selection and multiple tools such as Data Miner, Phantombuster, ZapInfo, Outwith Hub, and more. Seating is limited.
Comments 7
In the example you provide for java in amsterdam, the results are 1,030. But when I scrape it using Insta Data I get 50 results in the excel spreadsheet. Can you provide assistance as to why this is and not all the profiles extract on the spreadsheet? Yes, I have the Autopagerize extension.
Thank you! 🙂
Author
Al, click on the Instant Data SCraper icon after you have scrolled through the results you would like to collect. I hope it helps!
Gotcha! It does help in answering my question, thank you 🙂 So Insta Data scrapes only the data that has been scrolled through and on the screen. So if you have 100 pages of results, do you know of a quick way to scrape all 100 pages instead of first scrolling through it all? I appreciate your assistance!
Author
Correct, it scrapes the data on the screen.
Note, Github has a defense mechanism against too many pages viewed within a short period of time. While there are scripts that would auto-scroll for you (but would fail if Github “notices” the activity!), I’d recommend not scraping more than a few hundred results at a time.
Sure that makes sense! So Github’s defense mechanism is toward pages viewed or profiles viewed? So simply scrolling through the pages using Autopagerize might set off an alert?
Author
It might 🙂
Thank you 🙂