(This post is about what Google can’t find, with Australia- and NZ- based examples. It should be useful for everyone, no matter where they live.)

At the recent Sourcing Summits NZ and Australia I asked the audience to name some cases where web pages would not be found by Google. Examples provided included: “some people are not online” (at all!) and “if I am logged in to my bank, I hope Google doesn’t find this info”.
Further, we agreed, that if anyone is logged-in to a member site (whether paid or not), then the pages seen by that individual contain “inside” data, often personalized to the member, and therefore, in most cases, cannot be found by Google.
Another example brought up was “a page with search results”, using a search engine, or using any site providing search. Those results are pulled onto one page just for us to look at them that once. The pages with search results are usually short-lived; Google will not find them.
There are a few more general categories of web pages, that Google will not find, not covered by the above. One case to remember is that webmasters can tell Google to stay away from some pages. Websites can prevent Google from indexing portions of the sites, by providing directives in the file named robots.txt. Google will respect the rules.
It’s not true that Google can find “most of it” either (as someone said they’d hope). Here’s what the big picture looks like:

(By the way saying “Deep Web search on Google”, an expression I heard from an American colleague -who also claimed good skills in that – is not right. Deep Web is, by definition, what Google can’t find.)
Of course, Google finds LOTS and is worth extensively using for research.
It’s important, however, to straighten the expectations about what can be found and what can’t. Here’s a specific case that may not be clear upfront. Even if you do not have to log into a site – some of the site’s pages, dynamically created in response to a search, or, more generally, pages, pulling out from a database and including some info “dynamically”, just to show the page, may not be found by Google.
EXAMPLE
As an example, let’s consider a search for corporate members on the Recruitment Association RCSA
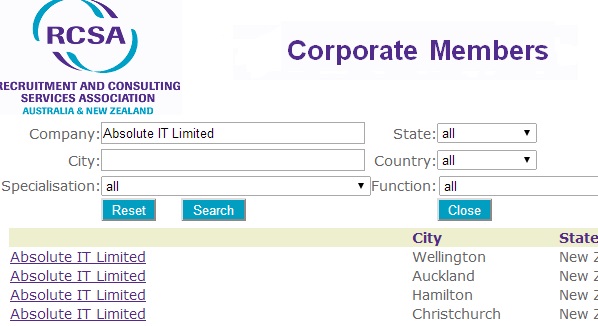
Sure enough, the page depicted above is “constructed dynamically” – and will not be found by Google.
Let’s also look at one of the results:
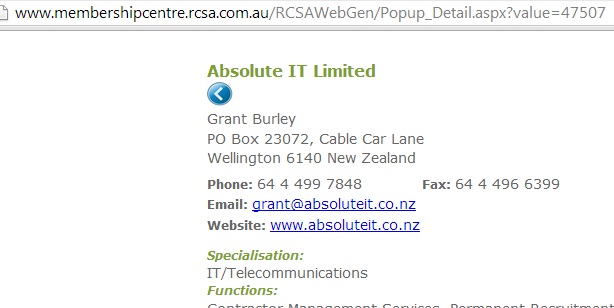
This page, while being “just” a listing page for a member, cannot be found by Google either! None of the four member listing pages found in the search above, can be found by Google. If you are in doubt, you can try searching for them: site:membershipcentre.rcsa.com.au “absoluteit.co.nz”
Generally, if you see a question mark ? in a page’s URL, like for the page above, chances are split in terms of Google finding the page. It may, it may not; it depends. (We’ll go into investigating a bit deeper in a future post.)
The moral of the story is: if it’s not straightforward whether a site can be “fully” X-Rayed for content, it is always a good idea to try searching both by X-Raying and “internally”. You might be finding more results by combining both ways. In the RCSA example above, internal searches will provide about 98% listings that X-Ray won’t.
For an in-depth Sourcing Methodologies study and specific Australia- and NZ-based examples to illustrate and work with, please check out my upcoming Webinar (Aug 26, 2014).